Introduction
In an era when organizations generate and manage information at unprecedented scale, the ability to extract insights from documents has become essential. Traditional manual workflows, once adequate for sorting, reading, and classifying documents, are no longer sustainable in the face of growing digital and physical data. This is where Document AI emerges as a transformative technology. Document AI refers to a suite of intelligent systems capable of reading, understanding, and acting upon documents with human-like accuracy and efficiency. At its core are three foundational technologies: Optical Character Recognition (OCR), Natural Language Processing (NLP), and Machine Learning (ML). Understanding how these components work – both individually and collectively – is key to appreciating the power and potential of modern document-processing solutions.
Definition
Document AI is the use of artificial intelligence – especially machine learning and natural-language processing – to automatically understand, extract, classify, and process information from documents such as PDFs, images, forms, and emails. It enables computers to read and interpret unstructured or semi-structured content the way humans do, turning documents into structured, usable data for automation and analysis.
The Role of OCR: Turning Unstructured Visual Data Into Text
OCR is the first gateway of Document AI, responsible for converting images, PDFs, and scanned documents into machine-readable text. Decades ago, OCR was limited to recognizing simple, printed characters with minimal accuracy. Today, thanks to deep learning, OCR systems can process noisy scans, varying fonts, complex layouts, and even handwritten text.
Modern OCR pipelines typically involve several steps:
1 Image Preprocessing:
Before recognition begins, the system enhances the image to remove distortions such as blur, skew, shadows, or background artifacts. Techniques like binarization, deskewing, denoising, and contrast adjustment help ensure that the text area is as clear as possible. This is especially critical for historical documents, faxes, or smartphone-captured images.
2 Text Detection:
OCR systems must identify where text exists on the image. Advanced models like EAST, CTPN, or Transformer-based detectors locate text regions by analyzing edges, contours, and visual patterns. This step is fundamental for documents with multi-column layouts, tables, or mixed media formats.
3 Text Recognition:
Here, deep neural networks – often recurrent or attention-based – decode the detected text regions into characters or words. Unlike earlier template-matching systems, modern recognition models learn from vast datasets, allowing them to generalize to new fonts, languages, and writing styles.
4 Layout Understanding:
More sophisticated OCR engines also interpret the document structure, identifying headings, paragraphs, tables, and key-value pairs. This structural information helps downstream processes understand not just what the text says but how it is organized.
Through these steps, OCR provides the raw textual data essential for further processing. Without accurate OCR, everything downstream – classification, extraction, analysis – becomes unreliable. It is the foundation upon which Document AI is built.
The Role of NLP: Bringing Meaning to Words
Once text has been extracted, the next challenge is understanding it. Human language is inherently complex – filled with ambiguity, context, idioms, and variations in tone. NLP allows machines to interpret this language in a meaningful and organized manner.
In the context of Document AI, NLP enables the system to perform tasks such as:
Tokenization and Part-of-Speech Tagging:
This involves breaking text into words, phrases, or sentences and identifying their grammatical roles. It is a building block for more complex understanding.
Named Entity Recognition (NER):
NER models detect important entities such as dates, locations, organizations, product names, or monetary values. This is crucial for use cases like invoice processing or legal document analysis.
Document Classification:
NLP models classify documents into categories – for example, contracts, resumes, claims forms, purchase orders, insurance records, and so on. Proper classification is essential for automated routing and indexing.
Sentiment and Intent Analysis:
While more common in customer-facing applications, these techniques are increasingly used in document review processes, particularly where subjective interpretation is needed.
Semantic Understanding:
Modern NLP models use embeddings (e.g., Word2Vec, GloVe, BERT, or Transformer-based models) to capture the meaning of words and sentences. This allows Document AI systems to understand context, relationships, and similarities across large text corpora.
Information Extraction:
This capability enables structured output from unstructured text. For example, extracting invoice numbers, due dates, names, addresses, or policy details from a large document. NLP combined with rules or ML models can identify and organize these fields automatically.
In many ways, NLP is the “intelligence” behind Document AI – transforming extracted text into usable, actionable information.
The Role of Machine Learning: Building Adaptive, Self-Improving Systems
Machine learning ties everything together by enabling Document AI systems to learn from data, adapt to new inputs, and continuously improve. While OCR and NLP are the visible components, ML acts as the engine that powers their accuracy and efficiency.
Training Models on Real-World Data:
ML models learn patterns based on thousands or millions of document samples. This helps the system generalize beyond pre-defined rules, handling new layouts, document types, or variations that would break traditional systems.
Feedback Loops and Human-in-the-Loop (HITL):
Document AI solutions often include human review workflows. When humans correct the system, those corrections are fed back into the model, improving future performance. This incremental learning allows the system to evolve in real organizational environments.
Automated Document Routing and Decision-Making:
ML algorithms identify which department or workflow a document should enter. For example, distinguishing between an insurance claim that needs urgent review and one that can be handled automatically.
Predictive Analytics:
Beyond extraction and understanding, ML enables predictions—such as estimating processing times, detecting anomalies, flagging fraudulent documents, or forecasting trends in document submissions.
Custom Model Fine-Tuning:
Organizations often deal with domain-specific language. ML allows Document AI systems to be fine-tuned for sectors like finance, healthcare, law, or logistics, improving accuracy for specialized terminology and structures.
Machine learning ensures Document AI systems are not static tools but dynamic technologies that grow with the organization.
How These Technologies Work Together
OCR converts visual data into readable text.
NLP interprets the meaning of that text.
Machine learning ensures the system improves continuously.
Together, they form a pipeline that can automatically:
- digitize paper archives
- classify multi-page document sets
- extract structured data
- validate and verify information
- integrate results into business workflows
This combination of technologies reduces manual labor, improves accuracy, accelerates data processing, and enhances compliance and auditability.
Real-World Applications of Document AI
Document AI has become indispensable across industries:
- Finance: automated invoice processing, loan document analysis, compliance checks.
- Healthcare: patient forms, lab reports, diagnoses, insurance claims.
- Legal: contract review, clause extraction, discovery workflows.
- Government: identity verification, record digitization, tax document handling.
- Logistics: bill of lading processing, customs forms, shipment documentation.
In each case, the synergy of OCR, NLP, and ML eliminates bottlenecks and accelerates decisions.
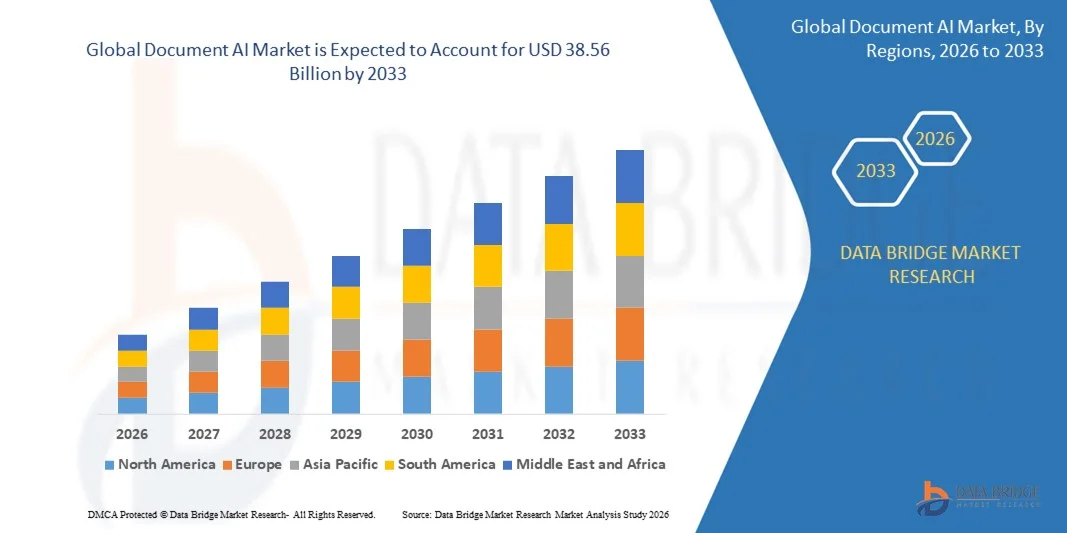
Growth Rate of Document AI Market
According to Data Bridge Market Research, the size of the global document AI market was estimated at USD 14.58 billion in 2025 and is projected to grow at a compound annual growth rate (CAGR) of 12.92% to reach USD 38.56 billion by 2033.
Learn More: https://www.databridgemarketresearch.com/reports/global-document-ai-market
Conclusion
Document AI represents a major leap in how organizations manage information. OCR enables accurate digitization, NLP brings understanding, and machine learning ensures adaptability and continuous improvement. Together, they form a powerful system capable of transforming vast amounts of unstructured data into actionable intelligence. As these technologies evolve, Document AI will continue to push the boundaries of automation, making document-centric workflows smarter, faster, and more reliable than ever before.